First Glimpses Inside the Mind
When we first opened the internal states of a training model, we had no idea what we would find. What emerged was not noise but structure — phase transitions, harmonic oscillations, convergence hierarchies, and synchronised instability events that no existing framework had predicted or described. These are some of the first images from that archaeological journey.
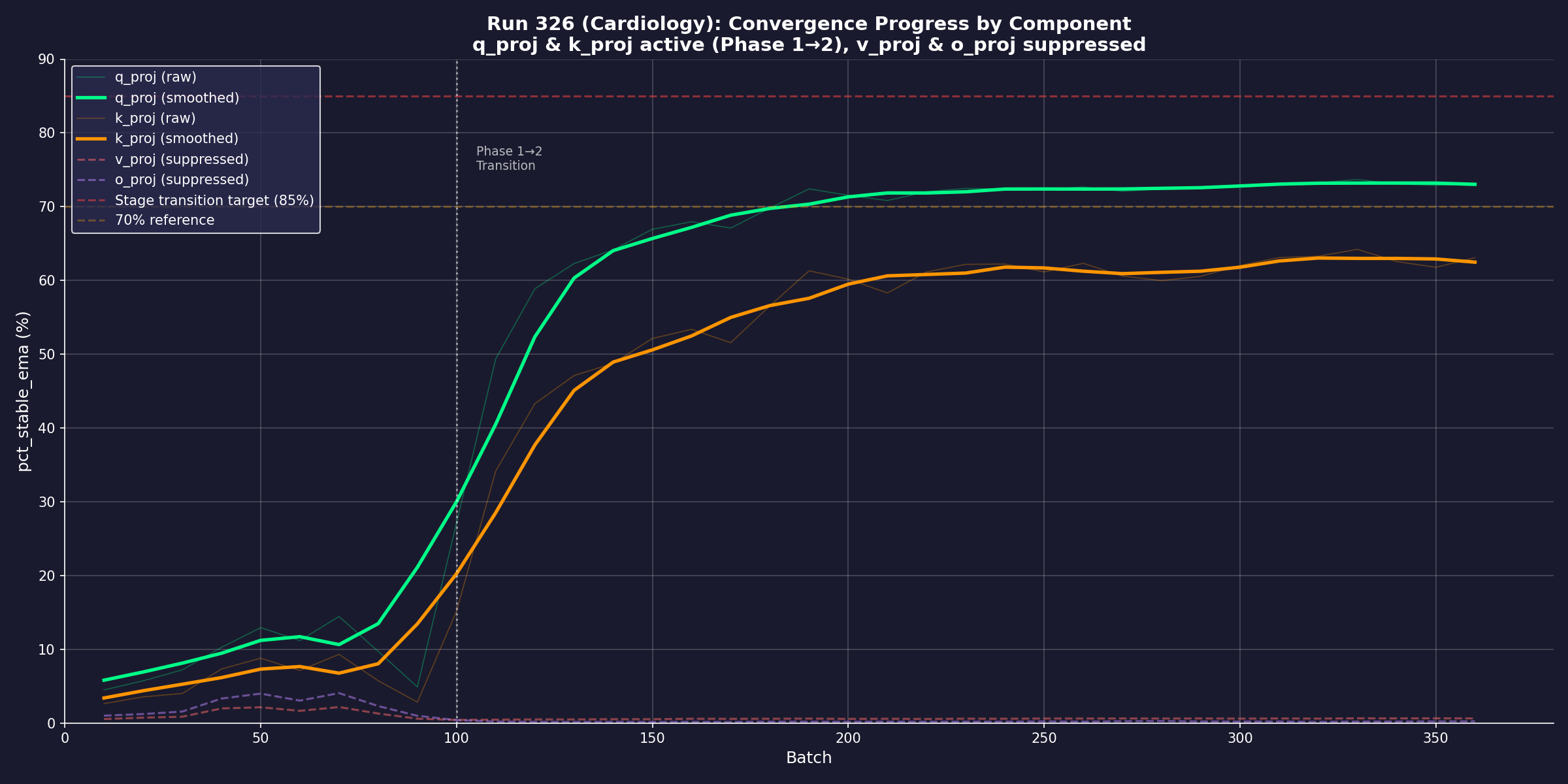
The moment a model learns. Run 326 (Cardiology specialisation):
convergence progress by attention component. The S-curve at batch 100 marks a clean
phase transition — q_proj and k_proj climb from single digits to 70%+ stability
while v_proj and o_proj are deliberately suppressed. This is not gradient descent
in the dark. It is visible, measurable learning.
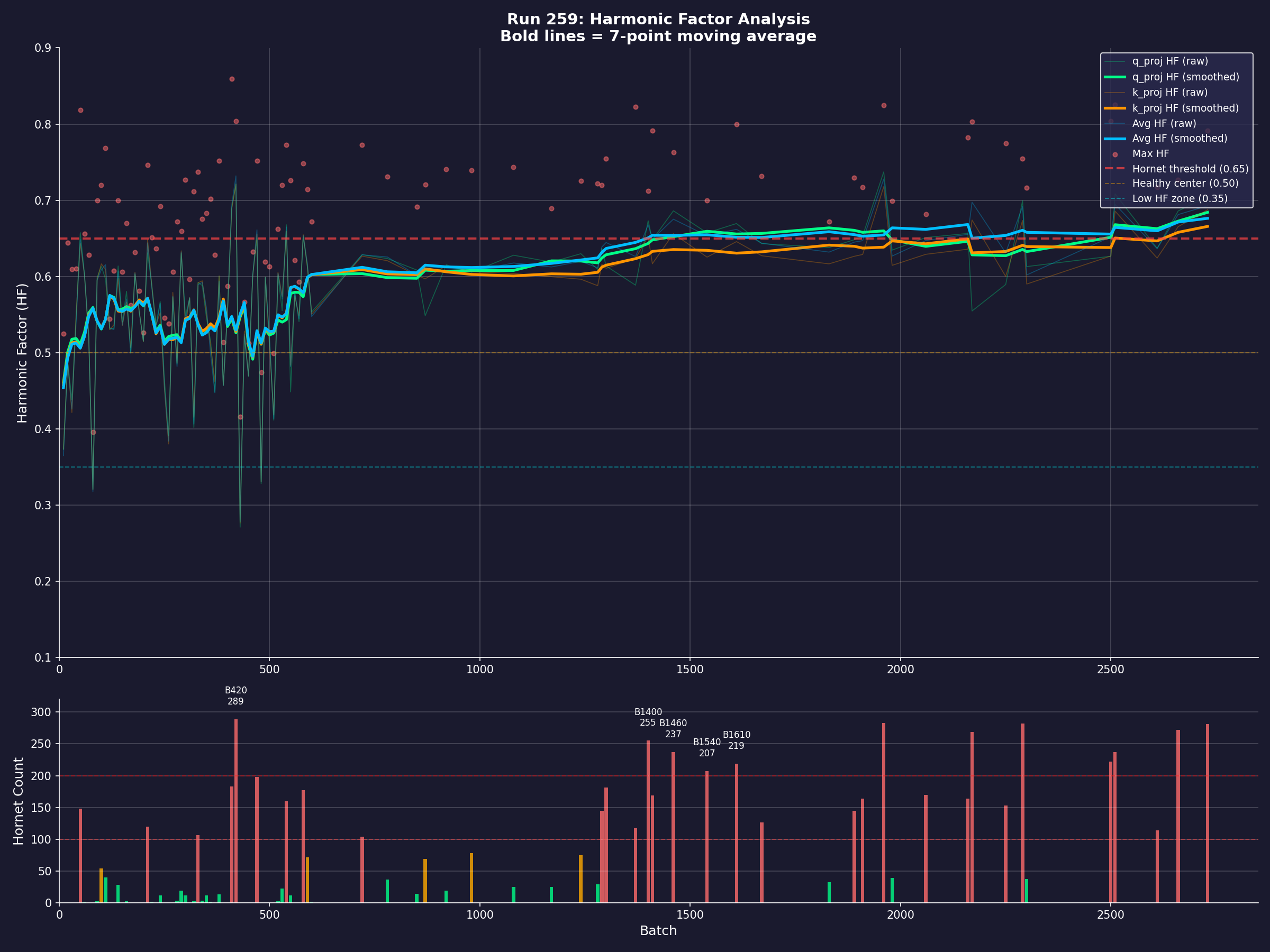
Harmonic structure in training dynamics. Run 259: the Harmonic Factor
(HF) tracks oscillatory behaviour across all attention components. Red dots mark
individual layer–component pairs breaching the 0.65 hornet threshold. The lower
panel shows hornet counts — synchronised instability spikes at B420, B1400, and
B1460 that correlate with curriculum transitions. The model’s internal dynamics
are not random. They are structured, periodic, and measurable.
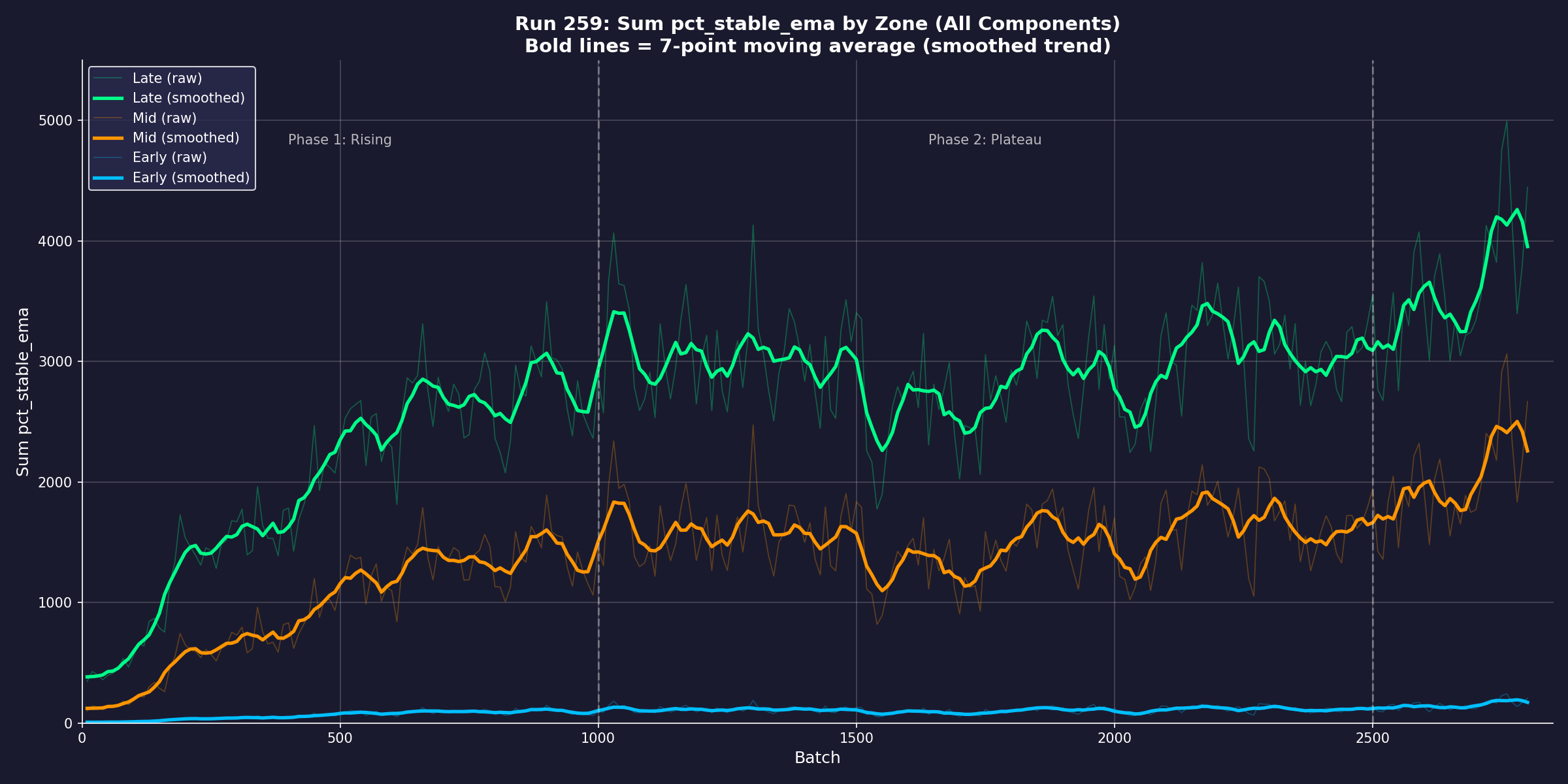
Where knowledge lives. Run 259: sum of pct_stable_ema by layer zone.
Late layers (green) carry the vast majority of convergence signal. Mid layers (orange)
follow at roughly half the magnitude. Early layers (blue) remain near-flat throughout
— a clear hierarchy showing that knowledge consolidation is concentrated in the
deeper transformer layers, exactly where the epistemic manifold predicts it should be.
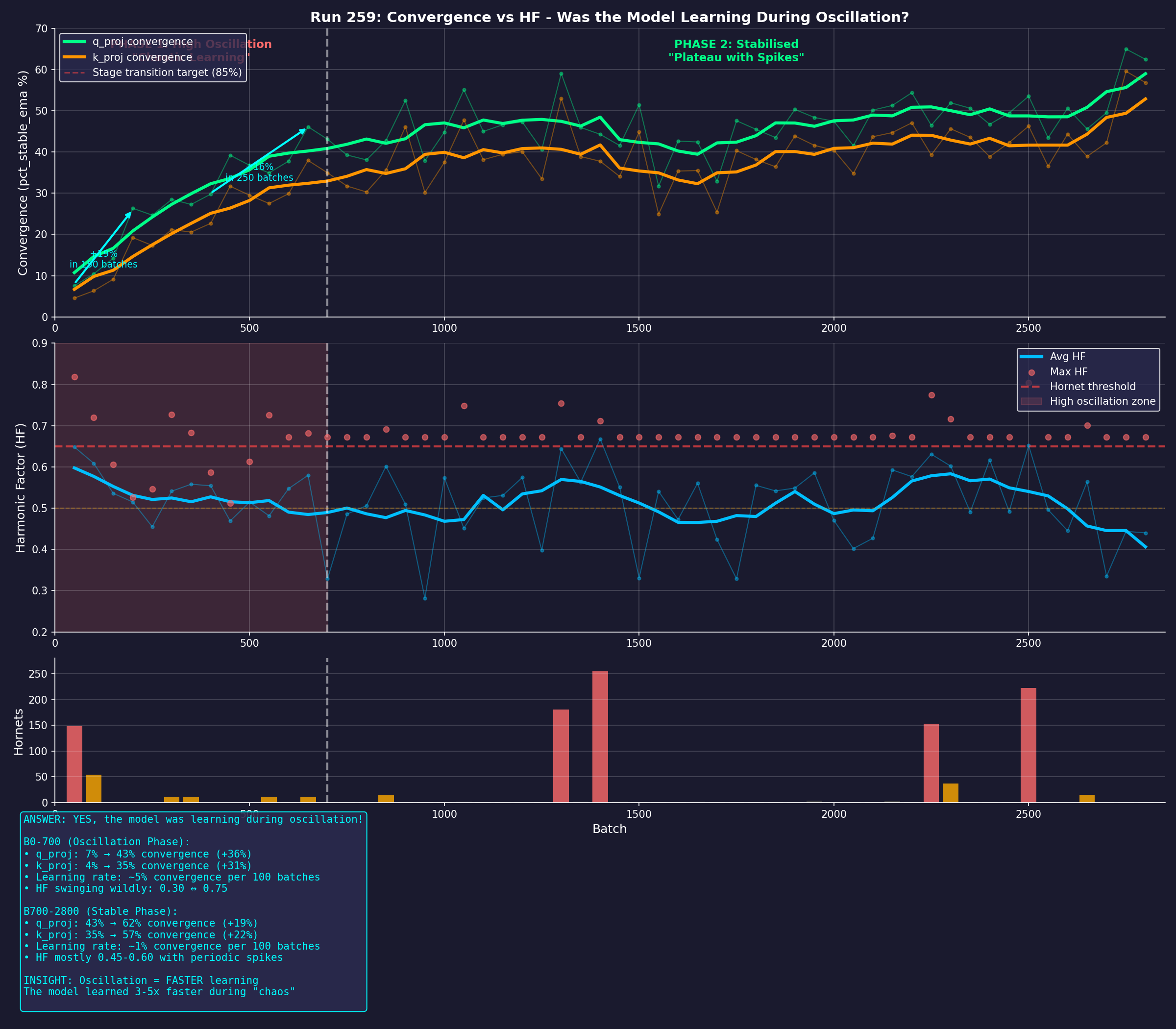
The full picture. Run 259: convergence, harmonic oscillation, and
instability events in a single view. Top panel: q_proj and k_proj convergence climbing
through oscillation. Middle panel: Harmonic Factor hovering near the 0.65 threshold.
Bottom panel: hornet spikes at curriculum-driven transition points. The key discovery:
the model was learning 3–5× faster during apparent “chaos” than during
the stable phase that followed. Oscillation is not failure. It is the signature of
rapid structural reorganisation.